

Gli appassionati di calcio ricorderanno la finale di Champions League del 2005 tra Milan e Liverpool. Sotto di tre reti, la squadra inglese recuperò lo svantaggio e chiuse i tempi regolamentari con un rocambolesco 3 – 3. La coppa venne assegnata ai calci di rigore. Jerzy Dudek, portiere del Liverpool, con la palla ferma sul dischetto e l'avversario in attesa di calciare, si esibì in una serie di movimenti distraenti sulla linea di porta prima di lanciarsi da una parte o dall'altra. Indusse all’errore 3 rigoristi su 5 (un pallone alto sopra la traversa e due parate) e il Liverpool alzò la coppa.
Per tirare un calcio di rigore occorre prestare attenzione a molti dettagli e rispondere in fretta alle mosse dell’avversario all’interno di un sistema di regole condiviso tra i giocatori. È un compito molto specifico, la cui risoluzione può essere elaborata dalle reti neurali di un’Intelligenza Artificiale (IA).
Uno studio pubblicato quest’anno su ArXive ha simulato, tra gli altri, proprio un gioco in cui un attaccante virtuale, guidato da un’IA, tenta di segnare a un giocatore, altrettanto virtuale, che difende una porta. La maggior parte delle IA oggi si basa sulle cosiddette reti neurali profonde, le deep neural networks (Dnn): alla macchina viene data in pasto una quantità enorme di dati da cui vengono estratte le risposte utili a risolvere il compito prefissato. Altre IA funzionano tramite un meccanismo di apprendimento diverso, quello per rinforzo (reinforcement learning): macchine di questo tipo sono state progettate per vincere ai videogiochi Atari (quelli della famiglia di Space Invaders o Pacman) o per vincere le partite di poker online (Pluribus è il nome del bot); mentre AlphaZero, l’applicazione di Google Deep Mind, è stata progettata per giocare e vincere a scacchi, Shogi e Go. Entrambe queste tipologie di IA oggi mostrano delle lacune che i ricercatori ritengono difficili da colmare.
Lo studio diretto da Adam Gleave, dottorando dell’università di Berkeley, in California, ha mostrato come far apparire ottuse queste macchine. È infatti possibile ingannare i più allenati sistemi di IA inserendo un’agente che somministra loro dati che non sono in grado di interpretare, “esempi antagonisti” (adversarial examples) li chiamano. Se il portiere virtuale dell’esempio si getta improvvisamente a terra, l’attaccante non è più in grado di interpretare correttamente i dati in entrata e non segna più. L’algoritmo dell’attaccante, allenato a riconoscere le mosse e le strategie di un portiere che fa il portiere, di fronte a un comportamento inatteso fallisce il compito prefissato. Lo potremmo chiamare effetto Dudek.
LEGGI ANCHE:
Del resto le IA più che vere e proprie macchine intelligenti sono degli idiot savant. Nel 2016 Microsoft aveva rilasciato Tay, un’IA programmata per imparare il linguaggio dei social media. È stata lanciata su Twitter e si è macinata milioni di messaggi, commenti, meme e foto, così da crearsi un modello delle regole del discorso umano online e replicarlo. Ha svolto a meraviglia il suo lavoro, tanto che ha iniziato a rispondere ai twit utilizzando un linguaggio razzista e misogino. I dirigenti hanno deciso di ritirarla nel giro di 24 ore.
La caratteristica precipua del machine learning e della sua evoluzione, il deep learning, è infatti la sua modularità. Le IA sanno svolgere alla perfezione un compito per volta, sia questo riconoscere un linguaggio parlato (è il caso del riconoscimento vocale), delle immagini (riconoscimento facciale) o elaborare i dati sulle preferenze dei consumatori. Ma non sanno fare due cose insieme, dimostrano scarsissima flessibilità e vengono facilmente messe in difficoltà quando portate al di fuori della propria comfort zone. Diversi studi oggi mostrano che questo limite è più ingombrante di quanto non si pensasse, soprattutto perché le macchine intelligenti sono uscite dai laboratori e si sono innestate in moltissimi contesti sociali.
Vengono usati ad esempio per incrociare dati clinici e formulare diagnosi. Uno studio pubblicato a marzo su Science ha mostrato che aggiungendo qualche pixel alle immagini ottenute dagli strumenti diagnostici, come un dermatoscopio, o semplicemente ruotando l’immagine originale, l’IA scambia casi di tumori benigni con casi maligni.
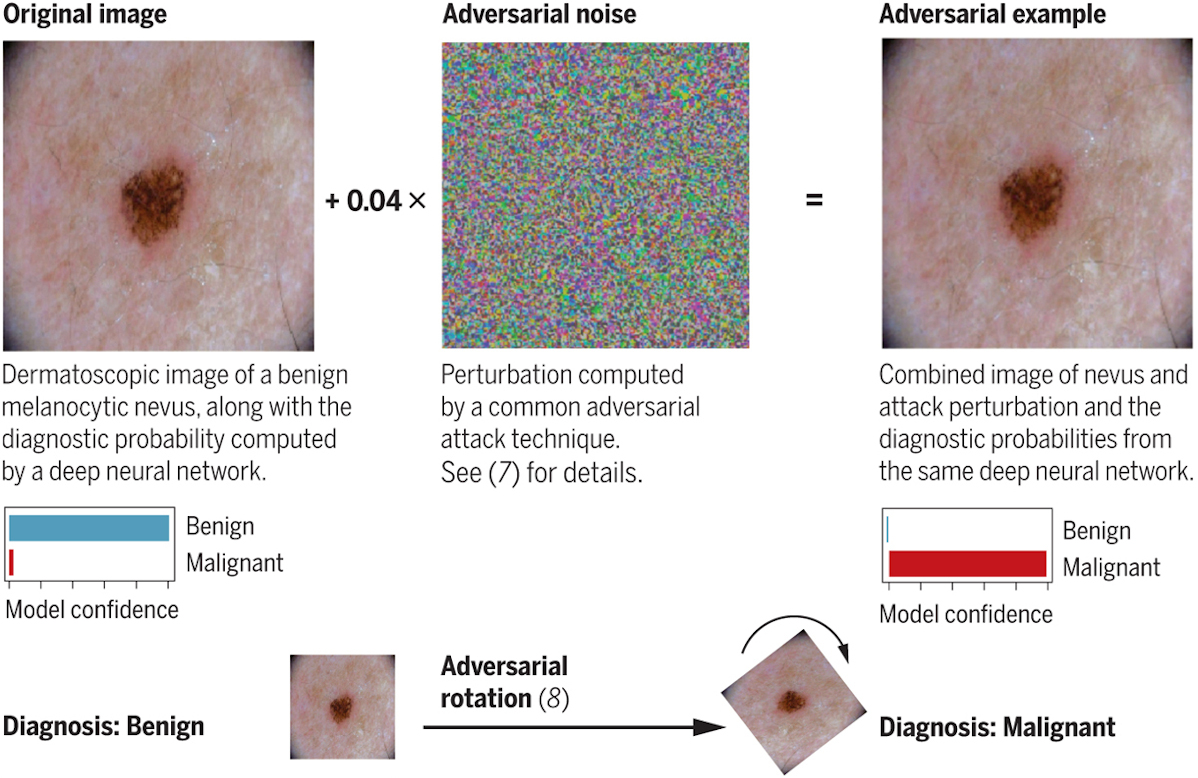
Anatomia di un dato ingannevole. Finlayson et al. 2019, Science, vol.363, issue 6433
Un altro ambito riguarda la sicurezza informatica. L’anno scorso un team di Google ha dimostrato che non solo si può spingere un’IA basata sul deep learning a fare specifici errori, ma addirittura si può sfruttare la sua tendenza a macinare dati per rieducarla a svolgere un compito per cui non era stata programmata. La ripetuta somministrazione di esempi ingannevoli può trasformare un sistema utilizzato per comprendere il linguaggio, come un banale chatbot, in un qualsiasi altro programma.
Un altro team di Google, nel 2013, dimostrò che modificando qualche pixel era possibile convincere una rete neurale profonda che stava guardando l’immagine di una libreria anziché di un leone. Un altro gruppo, due anni più tardi, mostrò che era facile fare vedere a una Dnn oggetti che non ci sono, come un pinguino in mezzo a una serie di linee ondulate.
LEGGI ANCHE:
Bastano lievi modifiche all’input e le IA si comportano, troppo facilmente, come dei creduloni. La cosa deve preoccupare perché in alcuni Stati vengono già impiegate per delegare decisioni importanti per la vita delle persone, come il rilascio di un mutuo o l’identificazione di comportamenti criminali. Per non parlare delle auto a guida autonoma: se il sistema di riconoscimento dei segnali stradali dovesse venire ingannato da qualche etichetta apposta su un cartello di stop, scambiandolo per un limite di velocità, dovremmo riconsiderarne completamente l’affidabilità e la sicurezza.
La preoccupazione ha già spinto gli studiosi a ragionare su possibili strategie di rimedio. Una potrebbe essere quella di allenare le IA a riconoscere gli inganni (adversarial training), sottoponendole a un elevato numero di esempi distorcenti. Nessuno tuttavia sembra essere ancora riuscito a trovare una soluzione a un problema che sembra strutturale e profondamente connaturato al deep learning. “È un campo davvero molto empirico il nostro” spiega in un articolo su Nature Dawn Song, computer scientist dell’università di Berkeley. “Se una cosa non funziona è difficile capire perché. Occorre semplicemente provare qualcos’altro”.

L’aggiunta di dettagli ingannevoli a un’immagine può far completamente cambiare l’output di una rete neurale profonda (deep neural network). Nature, vol. 574, 10 ottobre 2019, p.164
Quello che noi umani siamo diventati bravi a fare, ovvero generalizzare l’apprendimento da un compito specifico e trasferirlo a un altro, resta ancora lo scoglio più grande per una macchina. La ragione per cui noi riusciamo a farlo probabilmente ha a che fare con il modo in cui è evoluto il nostro cervello. Uno dei modelli ad oggi più accreditati è quello proposto dal neuroscienziato Michael Anderson sul riuso neurale. Abbiamo imparato a riutilizzare circuiti neurali evolutisi per un compito, motorio ad esempio, per risolvere altri problemi, di tipo linguistico ad esempio, generando nuove connessioni e nuovi circuiti neurali. È il caso dell’area di Broca, originariamente evolutasi a scopi motori, e oggi riutilizzata nel circuito di elaborazione del linguaggio. Allo stesso modo il nostro cervello a un certo punto si è trovato posto dinanzi alla sfida della lettura, un compito molto specifico per il quale non si erano evolute aree dedicate: abbiamo allora reclutato un’area della corteccia visiva, nel lobo occipitale, la Visual word form area (Vwfa) generando nuove connessioni e un nuovo circuito della lettura.
La mente umana resta una macchina ancora troppo complessa da riprodurre e le IA per ora sono solo in grado di simularne una funzione cognitiva alla volta, che pure ora appare soggetta a falle notevoli. Una strategia per far uscire l’IA dal guado dei dati ingannevoli potrebbe allora essere quella di cambiare il paradigma dominante. La soluzione consisterebbe nel dare in pasto alla macchina meno dati, ma insegnarle a trasferire la conoscenza appresa da un ambito all’altro, per farla assomigliare di più a un’intelligenza umana.
Si parla in questi casi di transfer learning: una rete neurale profonda che ha imparato a identificare un animale, come una giraffa ad esempio, impara a utilizzare alcuni aspetti già appresi per identificarne un altro, come un elefante. A seconda del compito, la macchina estrae da esperienze precedenti, di volta in volta, gli elementi più utili a risolverlo. Per fare questo potrebbe essere necessario recuperare alcuni elementi dell’IA simbolica, il paradigma in voga prima della diffusione del machine learning. Quest’approccio fornisce alla macchina una sorta di grammatica all’interno della quale deve muoversi, un insieme di regole che stabiliscono che nel mondo esistono oggetti discreti che entrano in relazione tra loro in vari modi.
È come se si dovesse insegnare alle macchine ad imparare ad imparare. In robotica quest’approccio è oggi molto promettente e in futuro probabilmente le macchine non riceveranno passivamente i big data, impareranno a manipolare l’ambiente circostante, creeranno dati attraverso le proprie interazioni e da questi impareranno.


